
From Attention to Transformer: A Brief History (work in progress)
Published:
How was the all mighty Transformer born?
Understanding Attention and Transformer
Attention in Seq2Seq
Seq2Seq is a family of models with an encoder-decoder architecture, proposed to handle sequence transformation tasks, such as machine translation, image captioning, and so on. The earliest Seq2Seq model (Sutskever et al., 2014) was powered by Recurrent Neural Networks (RNNs), where the encoder and the decoder each is a Long Short-Term Memory (LSTM). The input sequence is mapped to a fixed-length vector $c$ before $c$ is fed into the decoder for producing the target sequence. In the encoding stage, hidden states (memories) of the LSTM are updated in an autoregressive manner so that the hidden state at each timestep $t$ aggregates all the information seen so far. Such an architecture design requires the encoder to aggregate information for the whole input into the single vector $c$ before feeding it to the decoder.
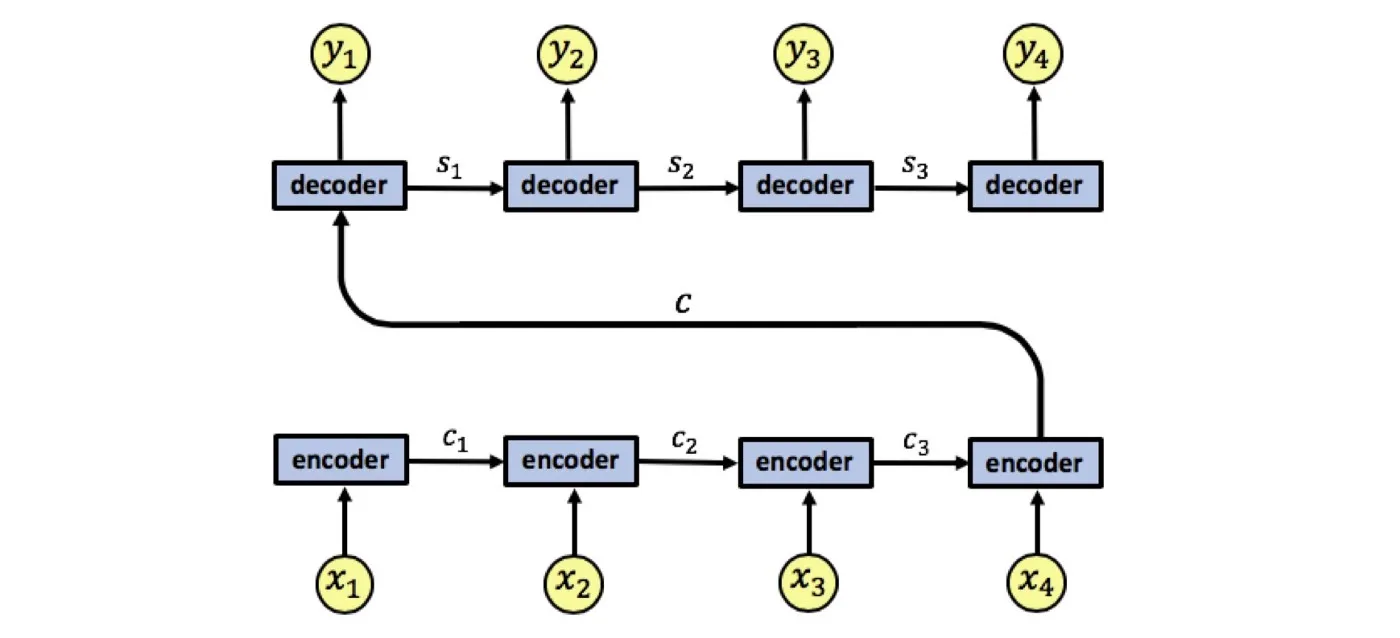
A major drawback is that compressing all the important information of an input sequence into a single vector might just be too hard for the encoder. Additionally, the decoder is asked to decompose the whole sequence provided with only one vector. In other words, the whole model is bottlenecked by the single fixed-length vector $c$. This motivated the attention mechanism.
References
[1] Sutskever et al. "Sequence to Sequence Learning with Neural Networks." NeurIPS 2014.